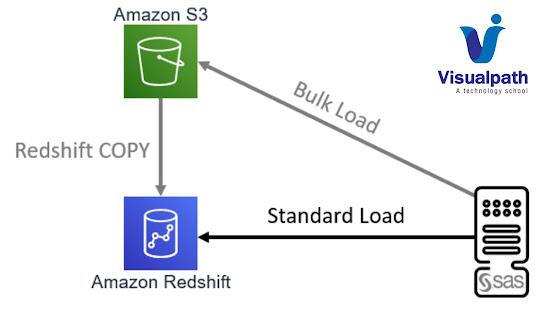
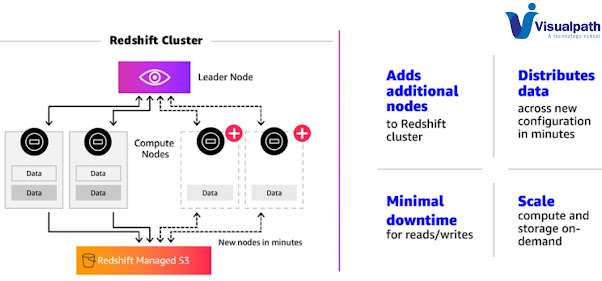
Amazon Redshift: Managing clusters using the console
Managing Amazon Redshift clusters using the console involves accessing the AWS Management Console and navigating to the Redshift service. - Amazon Redshift Online Training Here's a step-by-step guide on how to manage Redshift clusters using the console: 1. Accessing the AWS Management Console: Log in to your AWS account at https://aws.amazon.com/ and navigate to the AWS Management Console. 2. Navigating to Amazon Redshift: Once logged in, you can either search for "Redshift" in the AWS services search bar or navigate to the "Analytics" section and click on "Redshift." 3. Viewing Cluster List: In the Redshift dashboard, you'll see a list of your existing Redshift clusters. This page provides an overview of the clusters, including their status, cluster identifier, node type, and creation time. 4. Creating a Cluster: To create a new Redshift cluster, click on the " Create cluster " button. You'll be prompted to specify ...