Amazon Redshift | Loading & Unloading Data
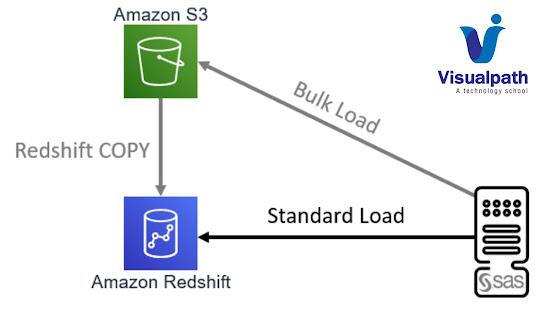
Loading and unloading data in Amazon Redshift involves moving data into and out of the Redshift data warehouse. This process is essential for populating Redshift tables with data from external sources and for extracting data from Redshift tables for analysis or archival purposes. There are several methods for loading and unloading data in Amazon Redshift: 1. Amazon S3: Amazon S3 (Simple Storage Service) is often used as an intermediary for loading data into and unloading data out of Redshift. You can use the `COPY` command to load data from files stored in S3 into Redshift tables, and the `UNLOAD` command to extract data from Redshift tables and store the results as files in S3. 2. Amazon DynamoDB: If your data resides in DynamoDB, you can use the AWS Data Pipeline service or AWS Glue to transfer data from DynamoDB tables to Redshift. - Amazon Redshift Online Training 3. AWS Data Pipeline: AWS Data Pipeline is a web service for orchestrating and automating the movement ...